Do you spend countless hours trying to find the right movie to watch? I certainly do! The premise of this project is to predict movie recommendations based on user ratings for films rated 75 or higher. By inputting a movie title into our application, we use the k-nearest neighbors (KNN) algorithm to predict ten recommendations. In this article, I’ll do my best to explain the process in layman’s terms.
First, we need to set up our environment. We’ll be using Jupyter Notebook, a text editor, or Google Colab. Then, we need to install the required packages by running pip commands for scikit-learn, fuzzywuzzy, python-Levenshtein, and sparse.
Setup:
Jupyter notebook
text editor
or
Google Colab
Installation:
pip install scikit-learn
pip install fuzzywuzzy
pip install python-Levenshtein
pip install sparse==0.1.1
Import Statements:
#classics
import pandas as pd
import numpy as np
import os
# algorithm
from sklearn.neighbors import NearestNeighbors
# sparse matrix
from scipy.sparse import csr_matrix
# string matching
from fuzzywuzzy import fuzz
from Levenshtein import *
from warnings import warn
Environment setup:
- Open your command-line (Terminal for MacOS, Anaconda Prompt for Windows)
- Navigate and download requirements.txt
- Run
conda create -n FILMLY python == 3.7Once the command completes, your conda environment should be ready to go. -
Now, we are going to add the proper python packages for this application. You will need to activate your conda environment:
source activate FIMLYon Terminal orconda activate FILMLYon Anaconda Prompt. Once your environment is activated, runpip install -r requirements.txt, which will install the required packages into your environment. -
We are also going to add an ipython Kernel reference to your conda environment, so we can use it in JupyterLab or text editor of choice.
-
Next, we will run
python -m ipykernal install — -user — -name FILMLY- -display-name “FILMLY(Python3)"=> This will add a JSON object to an ipython file. So when we are using JupterLab if you go this route. It will know that it can use this isolated instance of Python. - Deactivate your conda environment and launch JupyterLab. It would help if you remembered to see “FILMLY (Python3)” in the list of available kernels on the launch screen.(Jon-Cody Sokoll)
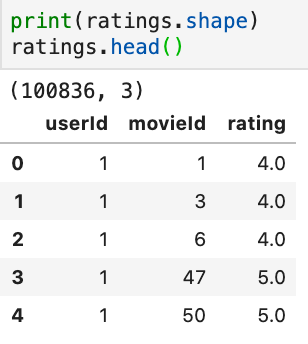
Next, we download our dataset from MovieLens, which includes movies.csv and ratings.csv files. We load and validate the data, then pivot the DataFrame to create a matrix of movie ratings by users. We convert this matrix to a sparse matrix and use it to calculate the distances between similar user movie recommendations.
Now we can load and validate our data.
# configure file path
data_path = os.path.join(os.environ['DATA_PATH'], 'MovieLens')
movies_path = 'movies.csv'
ratings_path = 'ratings.csv'#read data
movies = pd.read_csv(
os.path.join(data_path, movies_filename),
usecols=['movieId', 'title'],
dtype={'movieId': 'int32', 'title': 'str'})
ratings = pd.read_csv(
os.path.join(data_path, ratings_filename),
usecols=['userId', 'movieId', 'rating'],
dtype={'userId': 'int32', 'movieId': 'int32', 'rating': 'float32'})
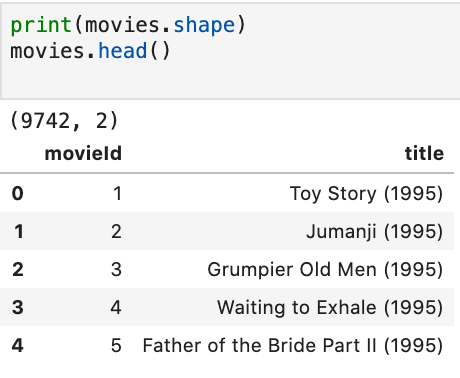
Next will view our movies data:
{kind=link}
{kind=link}
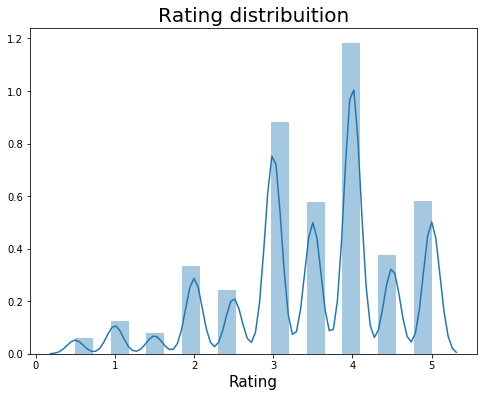
print("Top 10 Rating by user")
print(df["rating"].value_counts().head(10))
plt.figure(figsize=(8,6))
#Total rating distribuition
g = sns.distplot(df["rating"], bins=20)
g.set_title("Rating distribuition", size = 20)
g.set_xlabel('Rating', fontsize=15)
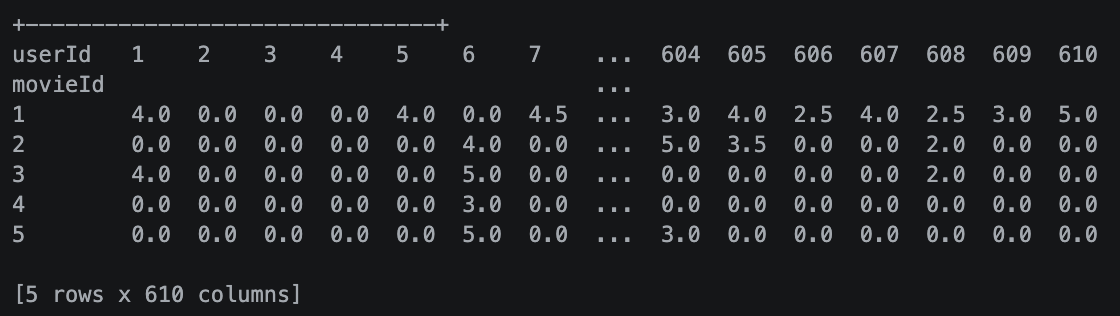
Now that both of our datasets we have to pivot the DataFrame and also make sure fo fill NA/NaN using a specified method. We use this to fill any holes in our data a simply default the value to zero. Don’t worry any values, not in our DataFrame will not be filled. This way That way it doesn’t interfere:
# Here we are making a pivot to set our dataset and features
features = ratings.pivot(index='movieId', columns='userId', values='rating').fillna(0)
# now will convert our DataFrame of movie features to scipy sparse matrix:
matrix_movie_features = csr_matrix(features.values)
# number of ratings each movie recived:
movie_count = pd.DataFrame(ratings.groupby('movieId').size(), columns=['count'])
{kind=link}
Let’s discuss how we are using the K-Nearest Neighbors(K-NN) algorithm in our project. To make movie recommendations, we need our data to be in an m x n array. Here, m represents the number of movies and n represents the number of users. We achieve this by pivoting our DataFrame, which sets the movie titles as rows and users as columns. Since our rating distribution is from 0 to 5, we will be calculating the distances between our vectors. To accomplish this, we need to perform linear algebra. (Kevin Liao)
{kind=link}
We will be using cosine similarity as our similarity metric for the nearest neighbor search in K-Nearest Neighbors. When we use KNN, it relies on us to set up our pivot and features in order to predict movies by calculating the distances between similar user movie recommendations. This is the reason why our dataset is sparse.
Here is an example of a KNN with 5 neighbors. We will set our parameters to 10 so we can predict ten movies. To learn more I recommend watching StatQuest: K-nearest neighbors, Clearly Explained
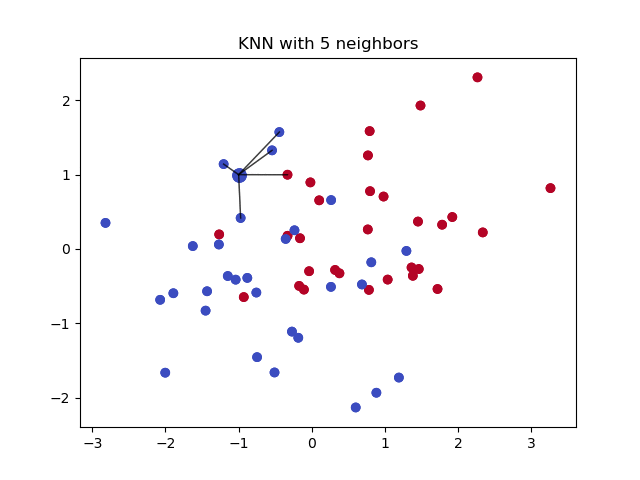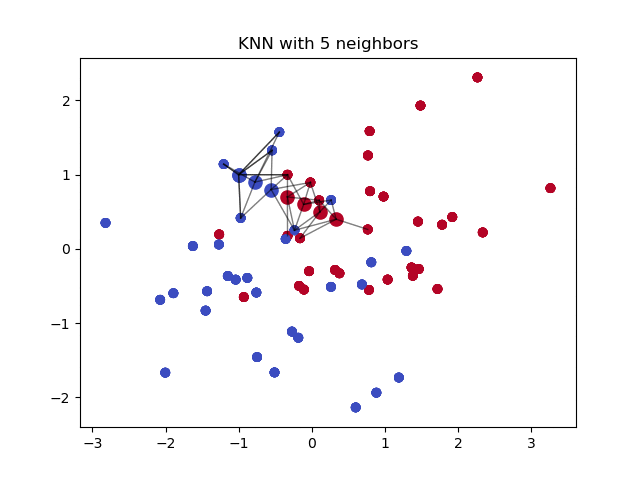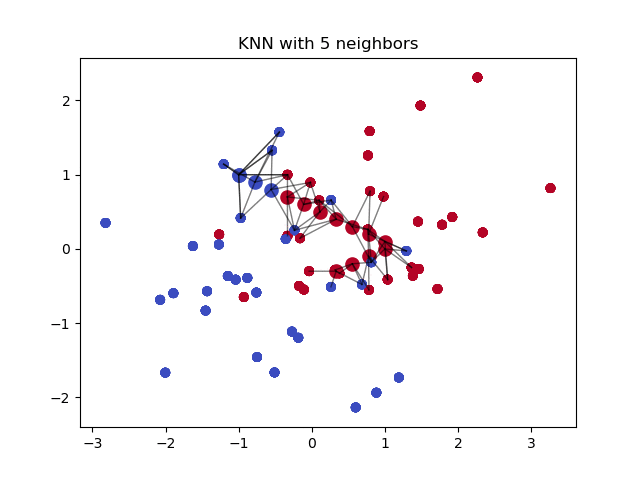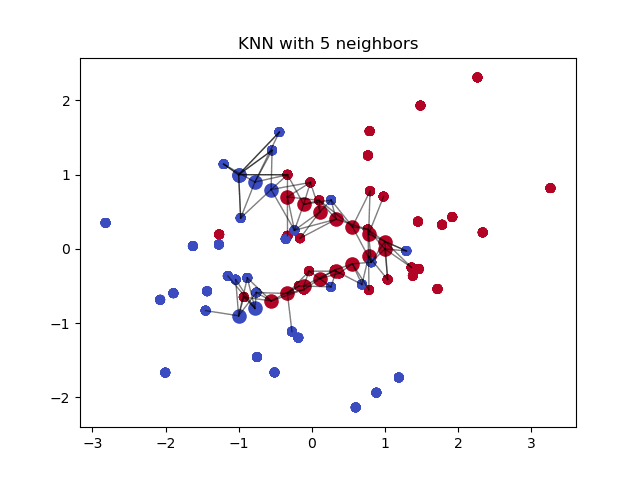{kind=link}
Parameters:
n_neighbors: int, default = 5
-
Will set ours to 10 algorithm: {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default = ‘auto’
- optional metric: string or callable, default ‘minkowski’
- ‘ball_tree’
- ‘kd_tree’
- ‘brute’ will use a brute-force search.
- ‘auto’
Read more about the ‘KNeighborsClassifier’ documentation for 'sklearn.neighbors'..
To summarize, we now have our sparse matrix complete and our DataFrame is transformed and ready to predict movies. The next step is to implement our KNN model with the following parameters:
# applying and defining our model
model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=10, n_jobs=-1)
#fit
model_knn.fit(movie_user_matrix_sparse)
Since we will not be utilizing natural language processing (NLP), we will use a fuzzy matching technique called FuzzyWuzzy to help match movie titles based on string similarity. FuzzyWuzzy calculates a ratio of similarity between two strings, using the Levenshtein Distance algorithm which measures the minimum number of edits needed to transform one string into another.
def recommendation(model_knn, data, mapper, favorite_movie, n_recommendations):
# fit
model_knn.fit(data)
# get our movie index
print(‘Film input’, favorite_movie)
index = fuzzy_matcher(mapper, favorite_movie, verbose=True)
print(‘Popular recommendations:’)
print(‘…..\n’)
distances, indices = model_knn.kneighbors(data[index], n_neighbors=n_recommendations+1)
raw_recommends = sorted(
list(zip(indices.squeeze().tolist(), distances.squeeze().tolist())), key=lambda x: x[1])[:0:-1]
# reverse mapping and unflattening
reverse_mapper = {v: k for k, v in mapper.items()}
# print recommendations
print(‘Here are more movies similar {}:’.format(favorite_movie))
for i, (index, dist) in enumerate(raw_recommends):
print(‘{0}: {1}, with distance of {2}’.format(i+1, reverse_mapper[index], dist))
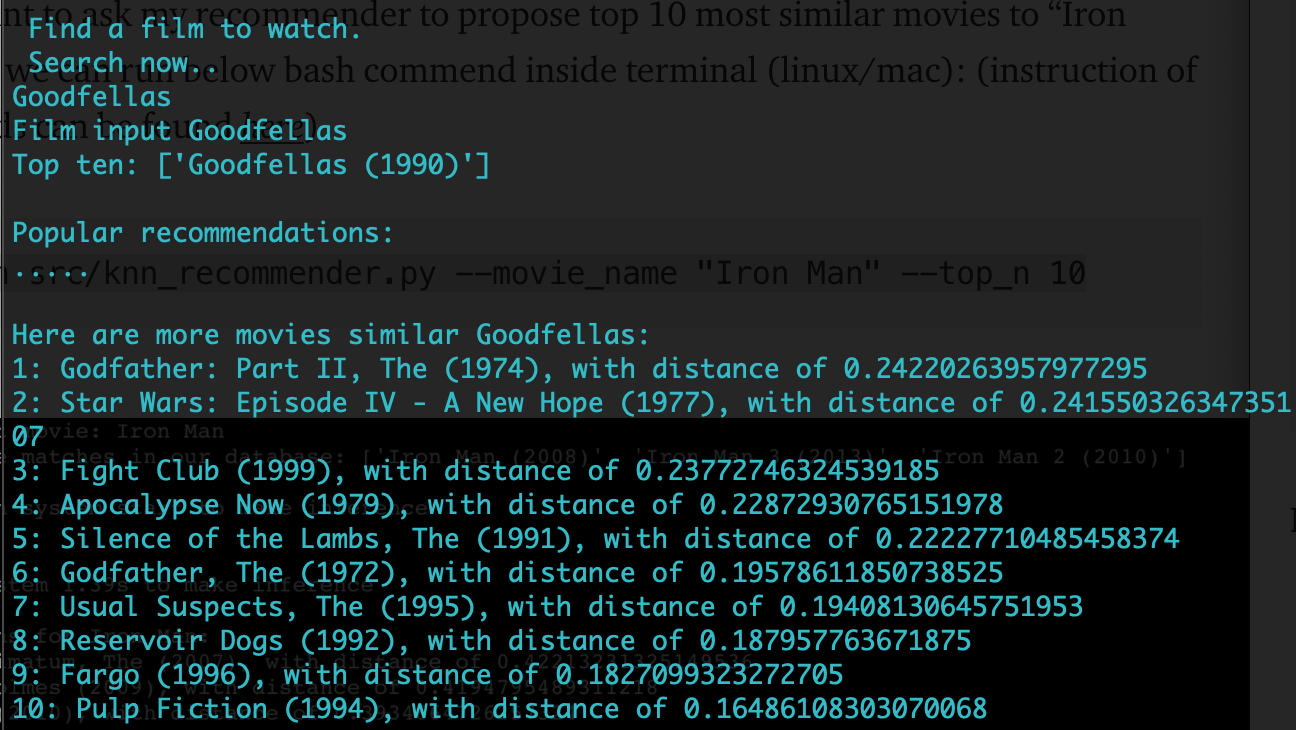
Now that we have set up our KNN model and implemented FuzzyWuzzy, we are ready to make movie predictions. We can input a favorite movie title into our recommendation function, and it will return the top ten recommended movies based on user ratings and similarity scores.
- Open your command-line (Terminal for MacOS, Anaconda Prompt for Windows)
- now run this command:
python or python3 [FILENAME].py
{kind=link}
And voila! We have our ten predictions! Please wait for a moment while the recommendations are generated. If you would like to add some fun elements to your application, you can try changing the colors within your command line or add a title card to your application like the following:
{kind=link}
def displayIntro():
print(" Find a film to watch.")
#
# Main
#
# Clears screen for opening logo :
clear_terminal()
# change colors:
# text = colored('Hello, World!', 'red', attrs=['reverse', 'blink'])
# print(text)
print(Fore.CYAN)
print("""
███████╗██╗██╗░░░░░███╗░░░███╗██╗░░░░░██╗░░░██╗
██╔════╝██║██║░░░░░████╗░████║██║░░░░░╚██╗░██╔╝
█████╗░░██║██║░░░░░██╔████╔██║██║░░░░░░╚████╔╝░
██╔══╝░░██║██║░░░░░██║╚██╔╝██║██║░░░░░░░╚██╔╝░░
██║░░░░░██║███████╗██║░╚═╝░██║███████╗░░░██║░░░
╚═╝░░░░░╚═╝╚══════╝╚═╝░░░░░╚═╝╚══════╝░░░╚═╝░░░
© MMXX JRGL.IM
"""
)
displayIntro()
type_and_will_predict_favorite_films = input(' Search now.. \n')
To create a new file, open your text editor and save it with a name like “utils.py”. Then, you can add the following code to your new file:
"""
Import Statements:
"""
from os import name, system
def clear_terminal():
if name == "nt":
# Windows
system("cls")
else:
# Linux or Mac
system("clear")
Second, navigate to your application.py or the [filename].py that you have named your project and add the following code to your Import Statements:
"""
Import Statements:
"""
# change font colors within command line
from colorama import Fore, Back, Style
# clears our terminal for title
from utils import clear_terminal #. where utils add [filename].
Once you have added the necessary code to your project, you will have an interactive interface to search for your films. If you would like to further customize your interface, you can explore ways to print colors in the Python terminal. Here is a guide that can help you get started.
In conclusion, as someone with a background in film and a true film buff, this was a fun project to work on. Although it’s not perfect and may occasionally make errors, I believe it can still provide useful recommendations. In the future, I may consider modifying the FuzzyWuzzy matcher and implementing natural language processing techniques to improve the analysis. This could include using a corpus of text and creating text visualizations to analyze token frequency in relation to our movie titles. However, that will be a topic for another blog post.
want to get in touch?
You can applaud my story on Medium here:
Resources:
MovieLens Latest Datasets, k -nearest neighbors algorithm, A Gentle Introduction to Sparse Matrices for Machine Learning, Here’s How to Build a Pivot Table using Pandas in Python, Building a movie recommendation system K-Nearest Neighbors Machine Learning, Machine Learning Basics with the K-Nearest Neighbors Algorithm, Collaborative filtering, Prototyping a Recommender System Step by Step Part 1: KNN Item-Based Collaborative Filtering:, Fuzzy String Matching in Python, Reverse Mapping and Unflattening, Comprehensive Guide to building a Recommendation Engine from scratch (in Python)